

Before we dive into the Polaris catalog, it’s important to understand the Iceberg table format. Organizations are focusing on this digital format not to combat global warming or melting icebergs, but to address rising data warehouse costs.
Iceberg is an open-source table format designed for handling large analytic datasets. It facilitates features like schema evolution, partitioning, and versioning, making data management more efficient and reliable.
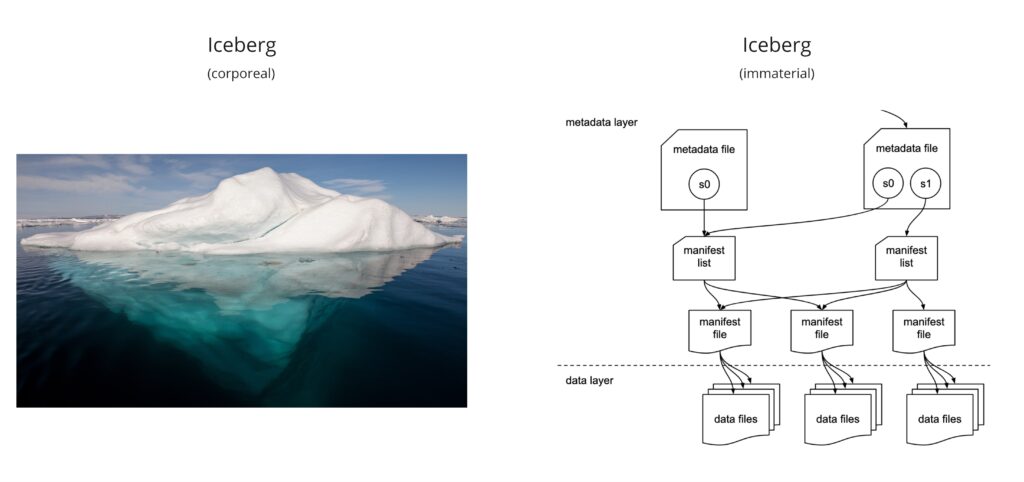
Before we go any deeper, let’s take a brief look at how Polaris and other data catalogs work with Iceberg’s table format.
Understanding Iceberg Catalogs
Iceberg is a table format. But simply having Iceberg formatted data doesn’t get you very far. In fact, data in Iceberg format is more difficult to access than plain csv or parquet files.
Catalogs, including the new Polaris Catalog from Snowflake can help centralize and organize Iceberg-formatted tables. With a catalog, we can take steps to access the Iceberg data more easily. What’s more, it allows users to take our first steps towards creating an open-source, provider-agnostic data warehouse that supports operations such as creating, dropping, and renaming tables.
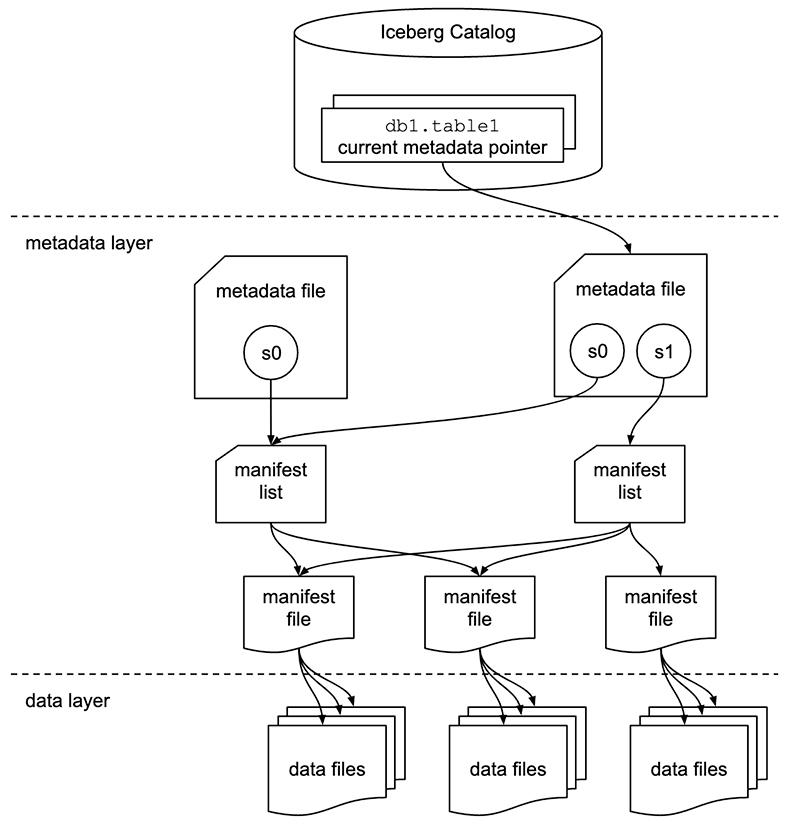
Since the catalog features that Polaris will provide overlap with core data warehouse functionality, you may be wondering why Snowflake would so graciously give us Iceberg table organization and tracking without asking anything in return?
Well, there is one key piece of the data warehouse missing: the compute engine.
The compute engine will interface with the data catalog and provide all the resources needed to interface with your data. Snowflake already provides a compute engine for Iceberg, and the compute engine is where the bulk of the data warehouse spend is. Simply put, Snowflake needs Iceberg to stay competitive.
Furthermore, there is a growing market of Iceberg query engines and catalogs, such as:
- Nessie
- Dremio
- Tabular
- Trino
- And others
Now that we’ve discussed what, let’s look at how all this works together.
Part 1: Using Iceberg with PyIceberg
To get hands on with the most basic implementation of an Iceberg “stack, “we’ll use “pyIceberg.” PyIceberg, as you might have already guessed from its name, can use Python as the compute engine, SQLite as the catalog, and local storage for the Iceberg tables.

For this basic example we will:
- Load some source data (parquet format),
- Create the catalog with pyIceberg,
- Load the data to the catalog using pyIceberg, then
- Query the data using pyIceberg and your local machine as the compute engine.
We can do this in under 50 lines of code with Python using PyIceberg. Below is a walkthrough of the code.
The only two dependencies for this are pyArrow and pyiIeberg
pip install pyarrow
pip install pyiceberg[pyarrow]
Then we can start loading in our example parquet data to a pyArrow data frame.
import pyarrow.parquet as pq
from pyiceberg.catalog.sql import SqlCatalog
# Create a pyarrow dataframe from a parquet file
df = pq.read_table("example.parquet")
We’ll also create the SQLite catalog.
This will create a SQLite database “pyiceberg_catalog.db” in the “warehouse” folder.
Now that we have our data and the catalog, we can populate it with the pyIceberg API.
# Create a namespace and table
catalog.create_namespace("default")
table = catalog.create_table(
"default.customer",
schema = df.schema,
)
# Load the table with the dataframe
table.append(df)
This creates a “default.db/customer” directory with our table data and table metadata in the warehouse directory.
If we drop and re-create the table and namespace, we can see that additional versions of the data and metadata are created in the /data and /metadata folders. The dropped tables will not show up in normal queries but can be recovered or permanently deleted later.
# Drop the table if it exists
namespace_tables = catalog.list_tables("default")
if ("default", "customer") in namespace_tables:
catalog.drop_table("default.customer")
catalog.drop_namespace("default")
# Create a namespace and table
catalog.create_namespace("default")
table = catalog.create_table(
"default.customer",
schema = df.schema,
)
# Load the table with the dataframe
table.append(df)
Finally, PyIceberg offers some simple query features, so we can query the Iceberg tables efficiently. We want to run this as our data warehouse in the cloud on highly available infrastructure.
Great! We have made interacting with local data more complicated. Really, we want to run this as our data warehouse, so in the cloud on highly available infrastructure.
# ----- query the Iceberg table -----
# Get the number of records loaded
total_records = len(table.scan().to_arrow())
print(total_records)
# Select 10 records from the table
table_sample = table.scan(
limit=10,
).to_arrow()
print(table_sample)
Now that we have the basics handled, we’ll want somewhere to store our Iceberg tables, an Iceberg Catalog, and a query engine. The catalog will be Polaris but we still need cloud file storage and a compute engine.
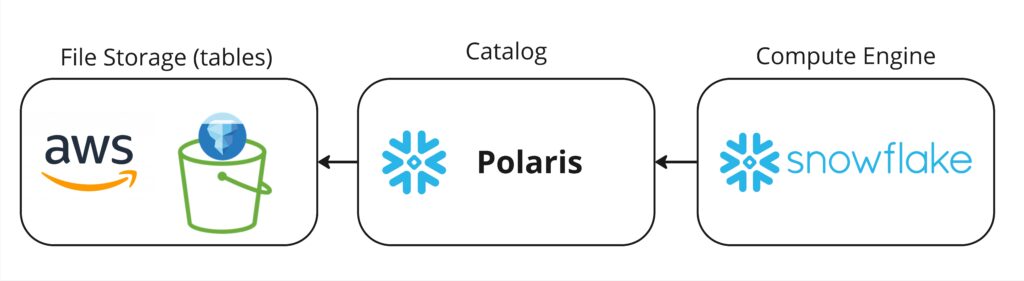
In part 2 of our Prepping for Polaris series, we’ll look at how to get value out of using Iceberg with a Snowflake-based architecture, where Snowflake is the compute engine.
Data stacks based on Apache Iceberg offer greater infrastructure flexibility than traditional data warehouses, but they may require more specialized engineering to implement.
If you have any questions about whether an Apache Iceberg-based stack is right for your organization, reach out to 7Rivers. Connect with our experts today!






