
Over the past year and a half, Large Language Models (LLMs) have revolutionized the technology industry, promising significant productivity gains. However, the realization of these promises has proven to be more complex than initially anticipated. LLMs, which are essentially neural networks, can sometimes produce inaccurate outputs with unwarranted confidence, a phenomenon known as hallucination.
Additionally, the landscape is filled with various techniques, pipelines, best practices, and frameworks, making it difficult to navigate the space. Central to this complexity is Retrieval-Augmented Generation (RAG). A quick search for “LLM RAG” reveals an overwhelming array of techniques, best practices, and frameworks, further adding to the confusion. This article aims to demystify RAG and provide up-to-date information about current techniques and methodologies.
What is RAG?
To keep it simple, Retrieval-augmented generation is a technique to improve the accuracy and reliability of the model’s response by augmenting the model with external data sources, data that was not used during the training often called Knowledge Base. Based on the complexity of the queries, there are two types of RAG.
- Naïve RAG: This method retrieves facts from a single document to answer straightforward prompts. For example, a simple query like “What is quantitative easing in the economy?” can be answered using data from a single government or central bank report.
- Multi-hop Retrieval: This approach extracts and combines information from multiple sources to address more complex queries. For instance, to answer “Explain the impact of quantitative easing on the economy,” the model might need to answer several sub-questions: What is quantitative easing? Why do central banks use quantitative easing? How is quantitative easing implemented? What are the short-term effects of quantitative easing on the economy? What are the long-term effects of quantitative easing on the economy? The answers to these sub-questions are typically found in multiple documents. By piecing together this information, the model can provide a comprehensive response to the complex query.
Why is RAG Important?
To talk about the importance of retrieval-augmented generation, it’s essential to understand the concept of model context windows. A context window is the amount of text information a model can process at one time, measured in tokens (words or parts of words). These tokens not only dictate the model’s processing capacity but also influence the cost of operating the model; the more tokens processed, the higher the expense. The context window determines how much data the model can retain and use to generate relevant responses. When dealing with large documents, the context window can be exhausted rather quickly. This is where RAG becomes particularly beneficial.
A RAG pipeline accesses the entire document data but retrieves only the relevant chunks needed to process the query and forwards this focused information to the model. This approach increases the amount of data the model can effectively use while reducing operational costs, as the model no longer needs to scan the entire document.
Additionally, Large Language Models (LLMs) tend to hallucinate more when processing unnecessary information. By providing only the essential data, RAG helps mitigate this issue, leading to more accurate responses.
LLMs do not have real time access to data, and are not always up to date, which can introduce hallucinations and inaccuracies. RAG addresses this by directing the LLM to authoritative data sources which can be cited, ensuring that the model’s responses are both current and accurate.
Notably, in 2024, the Retool Report indicated that about 36.4% of enterprise internal LLM use cases now employ some form of RAG. This highlights the growing importance of maintaining these pipelines and opens new discussions on best practices for their implementation and upkeep.
Who is RAG useful for?
After discussing what RAG is and its importance, the next question is: who will benefit from leveraging Retrieval-Augmented Generation? In a sense, we briefly touched on this when referencing the benefits of extending document visibility, reducing costs and hallucinations, and accessing real-time information. However, some might argue that not using RAG could be a “good enough” solution, avoiding the overhead and complexity of implementation and simply sticking to context windows. This leads us to the critical question: who is RAG really useful for?
Context windows have exploded in past few months and the industry trend seems to point to even larger context windows; some models even reaching into the millions of tokens. While context windows can indeed handle many tasks by processing and retaining relevant information within a broad scope, there are use-cases where RAG provides distinct advantages. These are some but not all ideal use-cases:
Large Organizations:
- Extended document visibility: Even though 1.5M tokens seems like a lot of content, and by all means it is having approximately 3,000 page book, it pales in comparison to the amount of information large organizations might need to process. Legal firms, financial institutions, and large corporations can all quickly saturate any context window currently available.
- Cost Efficiency: As previously discussed, RAG minimizes the amount of data the model needs to process at once, reducing operational cost.
Data Analysis Teams:
- Accurate Information Retrieval: Research teams in fields such as healthcare, academia, and technology often require the most relevant and up-to-date information from a wide range of sources. While context windows can help, RAG ensures comprehensive retrieval by pulling information from multiple documents, thus providing a more holistic view.
- Reducing Hallucinations: As discussed earlier, context windows alone may lead to hallucinations when dealing with large volumes of data. RAG helps mitigate this by focusing on retrieving only the necessary information.
Customer Service and Support Centers:
- Handling Complex Queries: For complex customer queries, context windows might not suffice. RAG can synthesize information from multiple sources, providing more comprehensive and accurate responses.
Content Creation:
- Efficient Data Handling: While context windows can manage information to some extent, RAG excels in handling large volumes of data efficiently, allowing content creators to focus on generating high-quality content.
RAG Reference Architectures
Although the implementation of a RAG pipeline can vary based on the techniques and frameworks used, the core elements remain consistent. The reference architecture below illustrates these fundamental components:
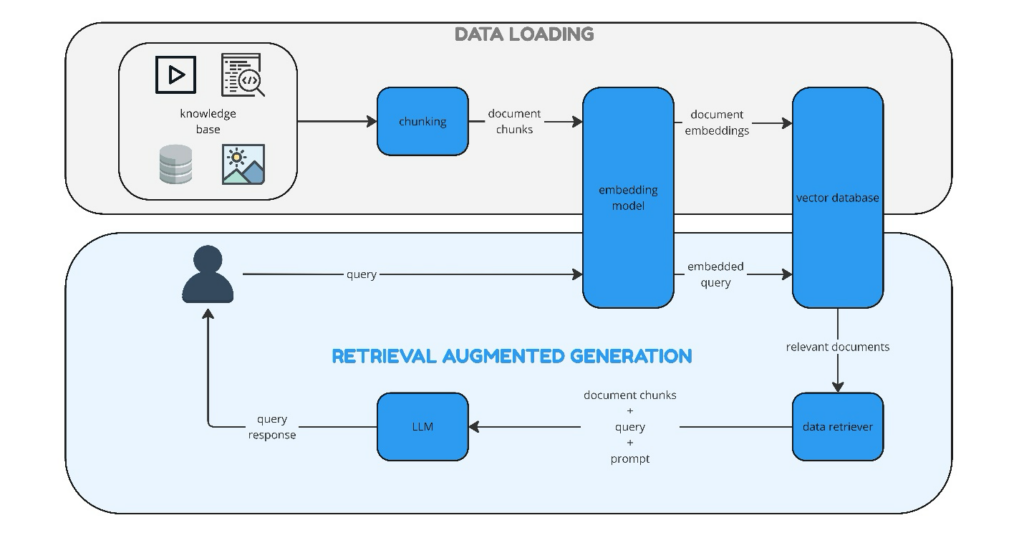
Data Loading
- External Data (Knowledge Base):
- Can include various data sources such as text documents, images, videos, and databases. There are many techniques of organizing this data to improve retrieval efficiency based on the type of queries. Complex queries usually leverage document hierarchies and research graphs.
- Document Hierarchies: Organizes documents in a hierarchical structure which helps in splitting required context across multiple documents.
- Research Graphs: Structures interconnected documents using graphs to facilitate the retrieval of related information.
- Can include various data sources such as text documents, images, videos, and databases. There are many techniques of organizing this data to improve retrieval efficiency based on the type of queries. Complex queries usually leverage document hierarchies and research graphs.
- Chunking:
- Purpose: Manages large documents by breaking them into smaller pieces, or chunks. There are various techniques for chunking methodologies, and two of the most popular ones are:
- Chunk Size: Adjusts the length of each chunk. Smaller chunks allow for more precise retrieval of relevant context, while larger chunks might encompass too much irrelevant information.
- Overlapping Chunks: Ensures that the context is not lost at the boundaries of the chunks.
- Embedding:
- The document chunks are transformed into numerical vector embeddings using an embedding model. These embeddings capture the semantic meaning of the text.
- Vector Database (Vector DB):
- The vectorized chunks are stored in a vector database. The vector database is optimized for searching and retrieving high-dimensional vectors, making it ideal for handling the embeddings generated from the document chunks.
- Purpose: Manages large documents by breaking them into smaller pieces, or chunks. There are various techniques for chunking methodologies, and two of the most popular ones are:
Retrieval-Augmented Generation
- Retrieve Relevant Information (Chunks) from Vector DB: This is a rather complex area and there are numerous techniques and ongoing research to optimize retrieval of chunks. Here are some of these techniques:
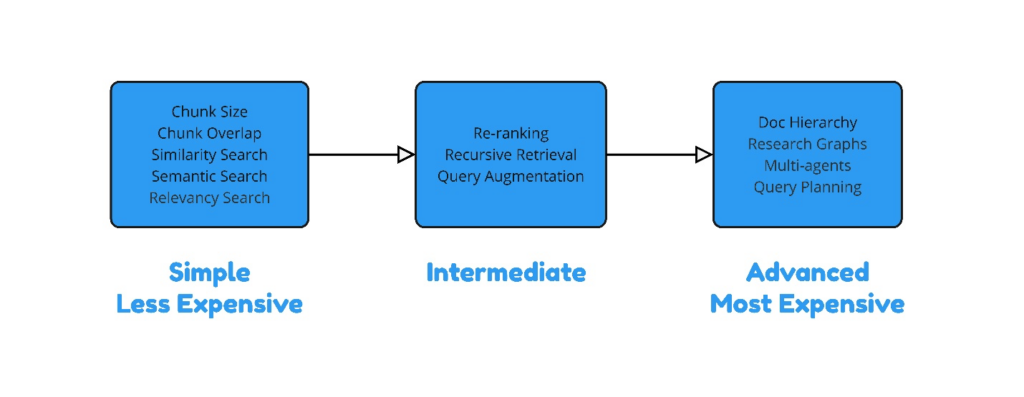
- Semantic Search: Uses the meaning of the query and the embedded document chunks to find the most relevant chunks.
- Similarity Search: Identifies chunks that are like the embedded query in the vector space.
- Relevancy Search: Focuses on retrieving chunks that are highly relevant to the specific query context.
- Re-ranking: Reorders retrieved chunks based on additional relevance criteria to improve the accuracy of the results.
- Recursive Retrieval: Involves multiple retrieval steps, refining results iteratively for better accuracy.
- Multi-agents: This is a whole different rabbit hole to discuss in a separate post, but the idea is to leverage multiple agents to parallelize and coordinate tasks such as data retrieval, re-ranking, and information synthesis, enhancing the efficiency and accuracy of the RAG process. Agents can work mimicking teams in an organization in a hierarchical approach or sequential.
- Querying:
- Embedding Query: Converting the query into an embedding that can be used to search the vector database.
- Data Retrieval: Using the embedded query to retrieve relevant document chunks from the vector database.
- Query Augmentation: Enhancing the original query with additional context or information to improve retrieval accuracy.
This was quite a lot, but the implementation of these techniques can be considerably simplified. Most popular LLM platforms already provide a way to leverage these RAG techniques natively. Here is a graph to help visualize complexity of implementation of these techniques:
Security of RAG
RAG pipelines have numerous decoupled pieces and data sources can vary widely. This architecture makes it great for scalability and flexibility of the system, but it represents a security thread having numerous potential points of failure. Ensuring robust security measures across all stages of the RAG pipeline is essential to protect sensitive data and maintain system integrity.
It is important to maintain proper authentication and authorization using services like multifactor authentication, single sign-on, and role-based access control, along with best practices techniques for data privacy.
References
- What is RAG? – Retrieval-Augmented Generation AI Explained – AWS (amazon.com)
- What Is Retrieval-Augmented Generation aka RAG | NVIDIA Blogs
- A first intro to Complex RAG (Retrieval-augmented generation) | by Chia Jeng Yang | WhyHow.AI | Medium
- The new State of AI report: Real use cases and the AI stack | Retool Blog | Cache
About 7Rivers Inc.
7Rivers, headquartered in Milwaukee, champions remote working, encouraging its team of engineers and innovators to develop trailblazing solutions that streamline business operations and open new revenue avenues, leading companies toward a future augmented by intelligence. 7Rivers leads businesses through the intricacies of digital transformation in a rapidly evolving market landscape. As a Snowflake® Partner, the company is inspired by nature and the limitless potential of machine learning and AI, guiding leaders to harness data’s value for unparalleled success. Contact us to learn more.





